¶ Balkonkraftwerke

Vor einem Fenster des Davinci-Labors befinden sich zwei Balkonkraftwerke mit jeweils zwei Paneelen. Die Leistungsdaten werden über ein OpenDTU ausgelesen und in Home Assistant gespeichert.
¶ Aufbau
¶ Westliches (Rechtes) Balkonkraftwerk
Fläche: 175cm x 110cm (pro Panel, 2 Panels)
Neigungswinkel: 35°
¶ Östliches (Linkes) Balkonkraftwerk
Fläche: 175cm x 110cm (pro Panel, 2 Panels)
Neigungswinkel: 25°
¶ Analyse
Für die Analyse wurde ein Datensatz aus Home Assistant im Zeitraum vom 03.08.2025 bis zum 04.05.2026 exportiert. Die Rohdaten findest du hier
Die Rohdaten enthalten stündliche Messwerte des Energieertrags. Für die Auswertung wurde jeweils der tägliche Maximalwert pro Anlage betrachtet.
¶ Monatlicher Ertrag
| Monat | West | Ost |
| 2025-09 | 58243 Wh | 56918 Wh |
| 2025-10 | 38738 Wh | 35950 Wh |
| 2025-11 | 20736 Wh | 19478 Wh |
| 2025-12 | 13324 Wh | 12547 Wh |
| 2026-01 | 23961 Wh | 23061 Wh |
| 2026-02 | 30680 Wh | 28104 Wh |
| 2026-03 | 33132 Wh | 30931 Wh |
| 2026-04 | 108700 Wh | 100490 Wh |
| 2026-ß5 | 18864 Wh | 18104 Wh |
¶ Ergebnisse
Im betrachteten Zeitraum ergibt sich:
- Westliches Kraftwerk: 346,378 kWh (rechtes Kraftwerk)
- Östliches Kraftwerk: 325,583 kWh (linkes Kraftwerk)
Damit ist das westliche Balkonkraftwerk insgesamt etwa 6,4 % effizienter als das östliche.
Auch in der grafischen Auswertung zeigt sich, dass der tägliche Ertrag des Westlichen Systems in den meisten Fällen über dem des Östlichen liegt.
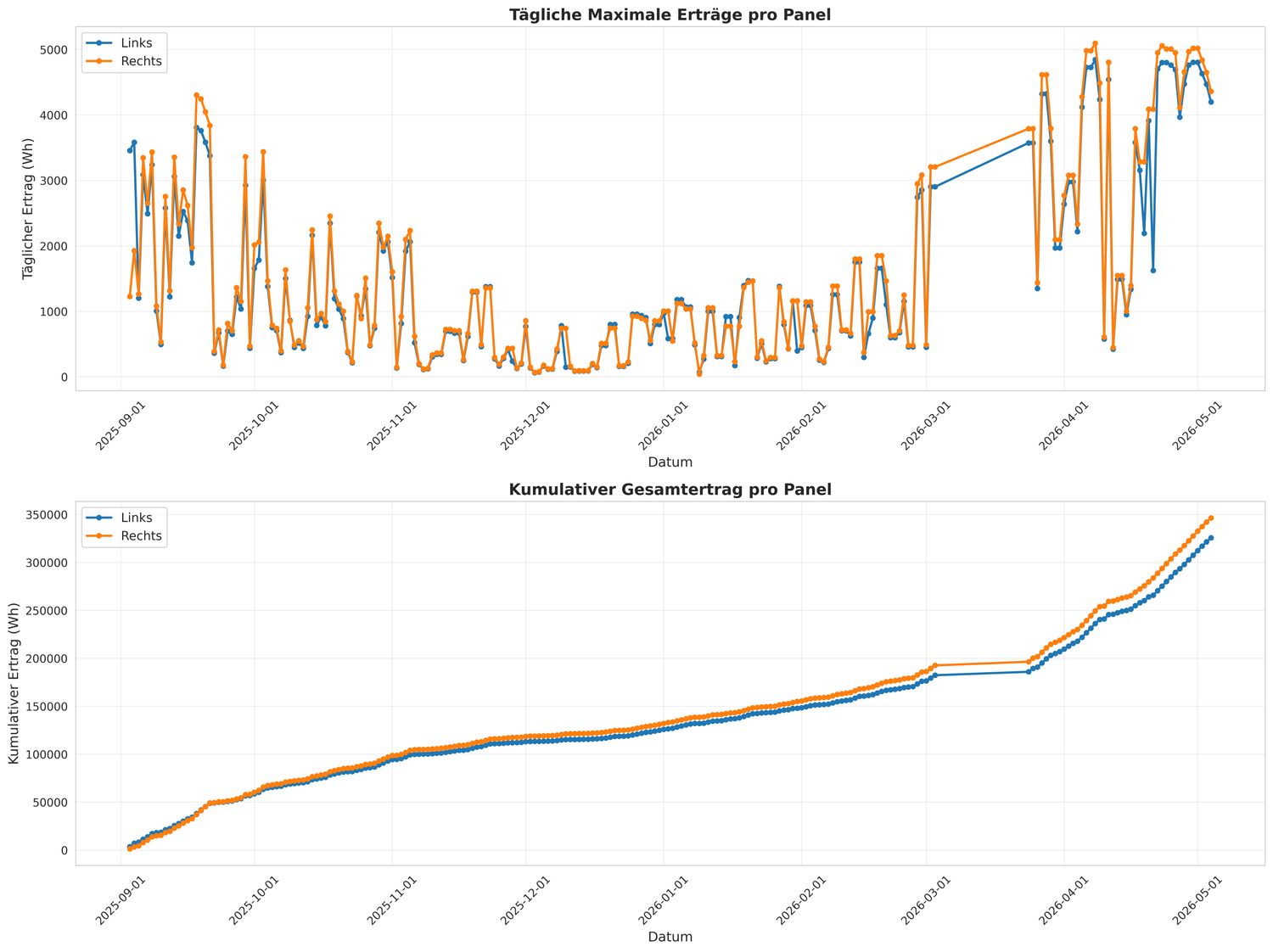
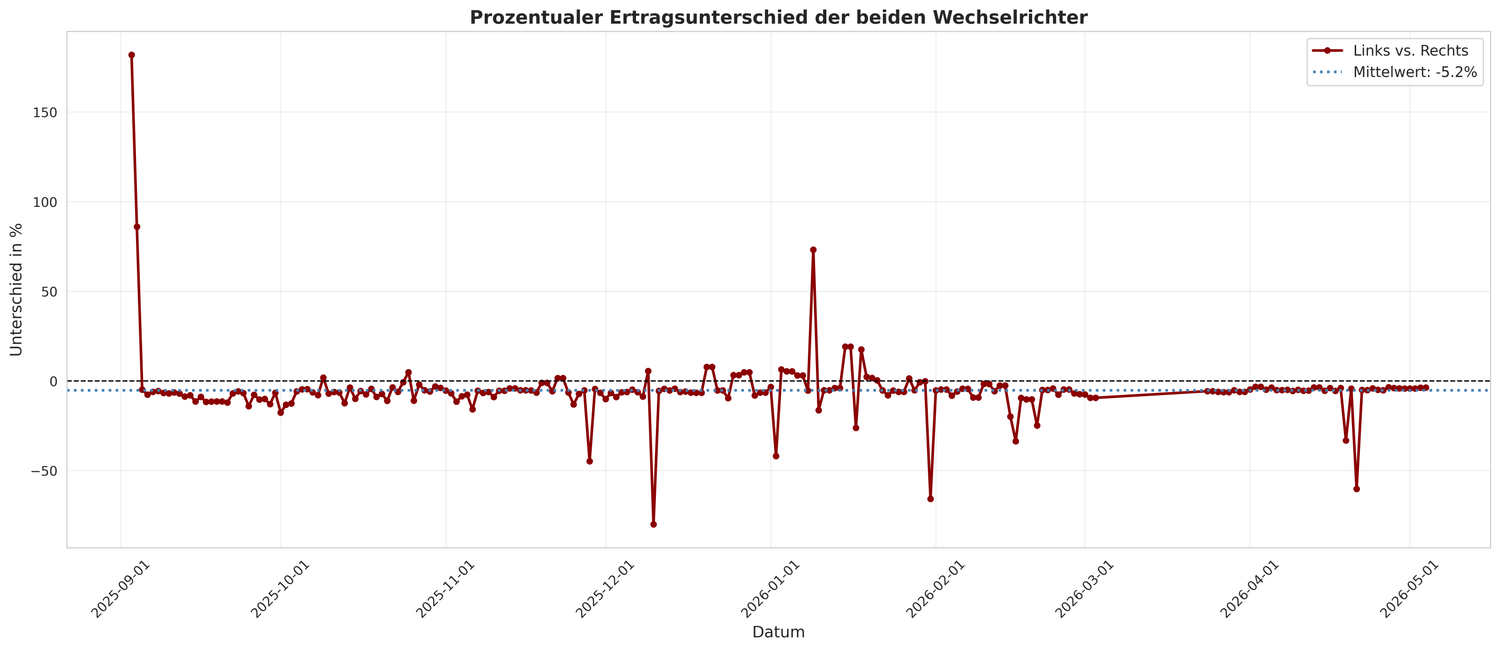
¶ Einschränkungen der Analyse
Die Ergebnisse sollten mit Vorsicht interpretiert werden, da mehrere Einflussfaktoren bestehen:
- Das östliche Kraftwerk ist seit dem 19. April 2024 in Betrieb und somit älter.
- Es existiert eine Datenlücke vom 02.03.2026 bis zum 24.03.2026.
¶ Gründe für diesen Effizienzunterschied
¶ Einfluss der Alterung
Photovoltaik-Module verlieren im Laufe der Zeit an Effizienz. Typische Werte (insbesondere bei günstigeren Modulen): (Quelle)
- 1. Jahr: ca. 1–3 % Leistungsverlust
- Danach: ca. 0,8–1,0 % pro Jahr
Da die Östliche Paneele etwa 1,5 Jahre älter sind, ergibt sich ein geschätzter Effizienzverlust von etwa:
- ≈ 2,9 % Gesamtverlust
- ca. 2,5 % im ersten Jahr
- ca. 0,5 % im darauffolgenden halben Jahr
Berücksichtigt man diesen Alterungseffekt, reduziert sich der reale Effizienzunterschied auf etwa 3,5 % zugunsten des Westlichen Kraftwerks.
¶ Einfluss des Winkels
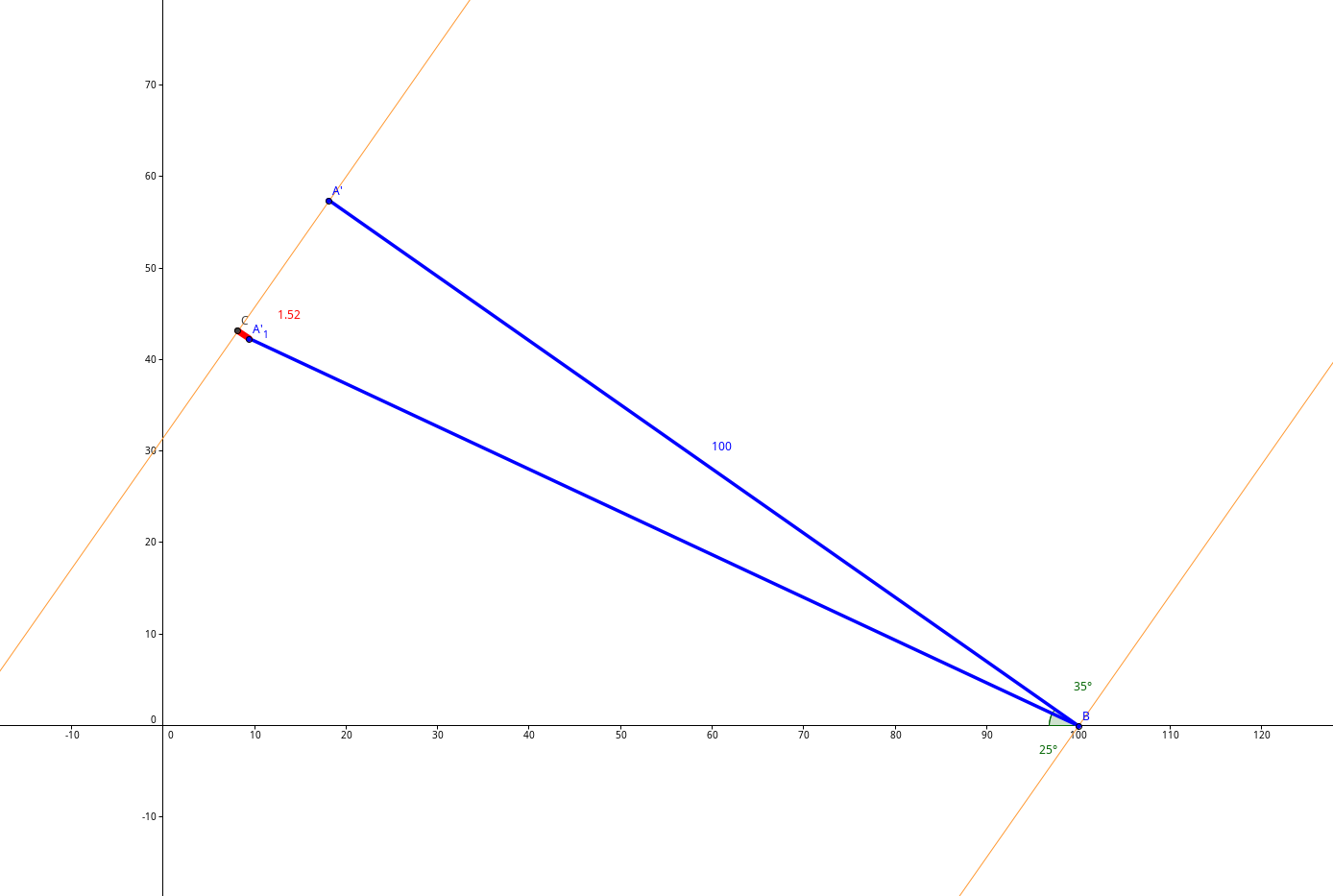
Die beiden Balkonkraftwerke sind mit unterschiedlichen Neigungswinkeln montiert. Laut einer Referenztabelle sowie einer Faustregel für Regensburg liegt der optimale Neigungswinkel bei etwa 34–35°.
Für die weitere Betrachtung wird daher angenommen, dass der optimale Winkel 35° beträgt und das rechte (westliche) Kraftwerk diesen optimalen Wert erreicht.
¶ Theoretischer Einfluss der Abweichung
Das linke (östliche) Kraftwerk ist mit einem Neigungswinkel von 25° installiert. Damit ergibt sich eine Abweichung von:
- Δθ = 10°
Zur Abschätzung des Einflusses des Neigungswinkels kann näherungsweise die cosinusförmige Abhängigkeit der Einstrahlung verwendet werden:
Leistung ∝ cos(θ)
Für kleine Winkelabweichungen vom Optimum ist insbesondere der relative Verlust durch den Unterschied relevant:
Relativer Ertrag≈cos(Δθ)
Damit ergibt sich:
cos(10∘)≈0,9848
Das Bild aus Geogebra zeigt es noch einmal anschaulicher
¶ Ressourcen
Das folgende Python-Skript wurde zur Auswertung der Daten verwendet:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from datetime import datetime
import seaborn as sns
# Set style
sns.set_style("whitegrid")
plt.rcParams["figure.figsize"] = (14, 8)
# Einlesen der CSV-Datei
df = pd.read_csv("history.csv")
# Konvertiere Datentypen
df["last_changed"] = pd.to_datetime(df["last_changed"])
df["state"] = pd.to_numeric(df["state"], errors="coerce") # Konvertiere zu numerisch
# Entferne Zeilen mit NaN in state
df = df.dropna(subset=["state"])
# Extrahiere das Datum (ohne Zeit)
df["date"] = df["last_changed"].dt.date
print("=" * 80)
print("BALKONKRAFTWERK EFFIZIENZ ANALYSE")
print("=" * 80)
print(f"\nDateibereich: {df['last_changed'].min()} bis {df['last_changed'].max()}")
print(f"\nVerfügbare Sensoren:")
print(df["entity_id"].unique())
# Gruppiere nach Sensor und extrahiere das Maximum pro Tag
max_per_day = df.groupby(["entity_id", "date"])["state"].max().reset_index()
max_per_day.columns = ["entity_id", "date", "max_yield"]
max_per_day["date"] = pd.to_datetime(max_per_day["date"])
print("\n" + "=" * 80)
print("TÄGLICHE MAXIMALE ERTRÄGE PRO PANEL")
print("=" * 80)
for sensor in df["entity_id"].unique():
sensor_data = max_per_day[max_per_day["entity_id"] == sensor]
total_yield = sensor_data["max_yield"].sum()
avg_yield = sensor_data["max_yield"].mean()
max_yield = sensor_data["max_yield"].max()
min_yield = sensor_data["max_yield"].min()
std_yield = sensor_data["max_yield"].std()
count_days = len(sensor_data)
print(f"\nSensor: {sensor}")
print(f" Anzahl Tage: {count_days}")
print(f" Gesamtertrag: {total_yield:.0f} Wh")
print(f" Durchschnitt/Tag: {avg_yield:.1f} Wh")
print(f" Maximum/Tag: {max_yield:.0f} Wh")
print(f" Minimum/Tag: {min_yield:.0f} Wh")
print(f" Std. Abweichung: {std_yield:.1f} Wh")
# Erstelle eine Pivot-Tabelle für Vergleich
pivot_data = max_per_day.pivot(index="date", columns="entity_id", values="max_yield")
# Berechne Statistiken für Vergleich
print("\n" + "=" * 80)
print("VERGLEICH DER PANEL-EFFIZIENZ")
print("=" * 80)
for col in pivot_data.columns:
total = pivot_data[col].sum()
avg = pivot_data[col].mean()
print(f"\n{col}:")
print(f" Gesamt: {total:.0f} Wh")
print(f" Mittel: {avg:.1f} Wh/Tag")
# Berechne relative Effizienz
if len(pivot_data.columns) == 2:
col1, col2 = pivot_data.columns[0], pivot_data.columns[1]
total1 = pivot_data[col1].sum()
total2 = pivot_data[col2].sum()
if total1 > total2:
efficiency_diff = ((total1 - total2) / total2) * 100
more_efficient = col1
else:
efficiency_diff = ((total2 - total1) / total1) * 100
more_efficient = col2
print(f"\n{'=' * 80}")
print(f"ERGEBNIS: {more_efficient} ist {efficiency_diff:.1f}% effizienter!")
print(f"{'=' * 80}")
# Erstelle Visualisierungen
fig, axes = plt.subplots(2, 1, figsize=(16, 12))
# Plot 1: Zeitreihe der täglichen Maxima
ax = axes[0]
for sensor in pivot_data.columns:
ax.plot(
pivot_data.index,
pivot_data[sensor],
marker="o",
label=sensor,
linewidth=2,
markersize=4,
)
ax.set_xlabel("Datum", fontsize=12)
ax.set_ylabel("Täglicher Ertrag (Wh)", fontsize=12)
ax.set_title("Tägliche Maximale Erträge pro Panel", fontsize=14, fontweight="bold")
ax.legend(fontsize=11)
ax.grid(True, alpha=0.3)
ax.xaxis.set_major_formatter(mdates.DateFormatter("%Y-%m-%d"))
ax.xaxis.set_major_locator(mdates.MonthLocator())
plt.setp(ax.xaxis.get_majorticklabels(), rotation=45)
# Plot 2: Kumulativer Ertrag
ax = axes[1]
for sensor in pivot_data.columns:
cumsum = pivot_data[sensor].fillna(0).cumsum()
ax.plot(cumsum.index, cumsum, marker="o", label=sensor, linewidth=2, markersize=4)
ax.set_xlabel("Datum", fontsize=12)
ax.set_ylabel("Kumulativer Ertrag (Wh)", fontsize=12)
ax.set_title("Kumulativer Gesamtertrag pro Panel", fontsize=14, fontweight="bold")
ax.legend(fontsize=11)
ax.grid(True, alpha=0.3)
ax.xaxis.set_major_formatter(mdates.DateFormatter("%Y-%m-%d"))
ax.xaxis.set_major_locator(mdates.MonthLocator())
plt.setp(ax.xaxis.get_majorticklabels(), rotation=45)
plt.tight_layout()
plt.savefig("balkonkraftwerk_analyse.png", dpi=600, bbox_inches="tight")
print(f"\n✓ Grafik gespeichert: balkonkraftwerk_analyse.png")
# Zusätzlicher Plot: prozentualer Ertragsunterschied
if len(pivot_data.columns) == 2:
col1, col2 = pivot_data.columns[0], pivot_data.columns[1]
percent_diff = (
(pivot_data[col1] - pivot_data[col2]) / pivot_data[col2].replace(0, np.nan)
) * 100
fig, ax = plt.subplots(figsize=(16, 7))
ax.plot(
percent_diff.index,
percent_diff,
color="darkred",
linewidth=2,
marker="o",
markersize=4,
label=f"{col1} vs. {col2}",
)
ax.axhline(0, color="black", linestyle="--", linewidth=1)
ax.axhline(
percent_diff.mean(),
color="steelblue",
linestyle=":",
linewidth=2,
label=f"Mittelwert: {percent_diff.mean():.1f}%",
)
ax.set_title(
"Prozentualer Ertragsunterschied der beiden Wechselrichter",
fontsize=14,
fontweight="bold",
)
ax.set_xlabel("Datum", fontsize=12)
ax.set_ylabel("Unterschied in %", fontsize=12)
ax.grid(True, alpha=0.3)
ax.xaxis.set_major_formatter(mdates.DateFormatter("%Y-%m-%d"))
ax.xaxis.set_major_locator(mdates.MonthLocator())
plt.setp(ax.xaxis.get_majorticklabels(), rotation=45)
ax.legend(fontsize=11)
plt.tight_layout()
plt.savefig("balkonkraftwerk_prozent_diff.png", dpi=600, bbox_inches="tight")
print("✓ Grafik gespeichert: balkonkraftwerk_prozent_diff.png")
# Erstelle noch eine Monatsanalyse
print("\n" + "=" * 80)
print("ANALYSE NACH MONATEN")
print("=" * 80)
max_per_day["month"] = max_per_day["date"].dt.to_period("M")
monthly_data = (
max_per_day.groupby(["entity_id", "month"])["max_yield"].sum().reset_index()
)
for sensor in df["entity_id"].unique():
sensor_monthly = monthly_data[monthly_data["entity_id"] == sensor]
print(f"\n{sensor}:")
for _, row in sensor_monthly.iterrows():
print(f" {row['month']}: {row['max_yield']:.0f} Wh")
print("\n" + "=" * 80)
print("Analyse abgeschlossen!")
print("=" * 80)